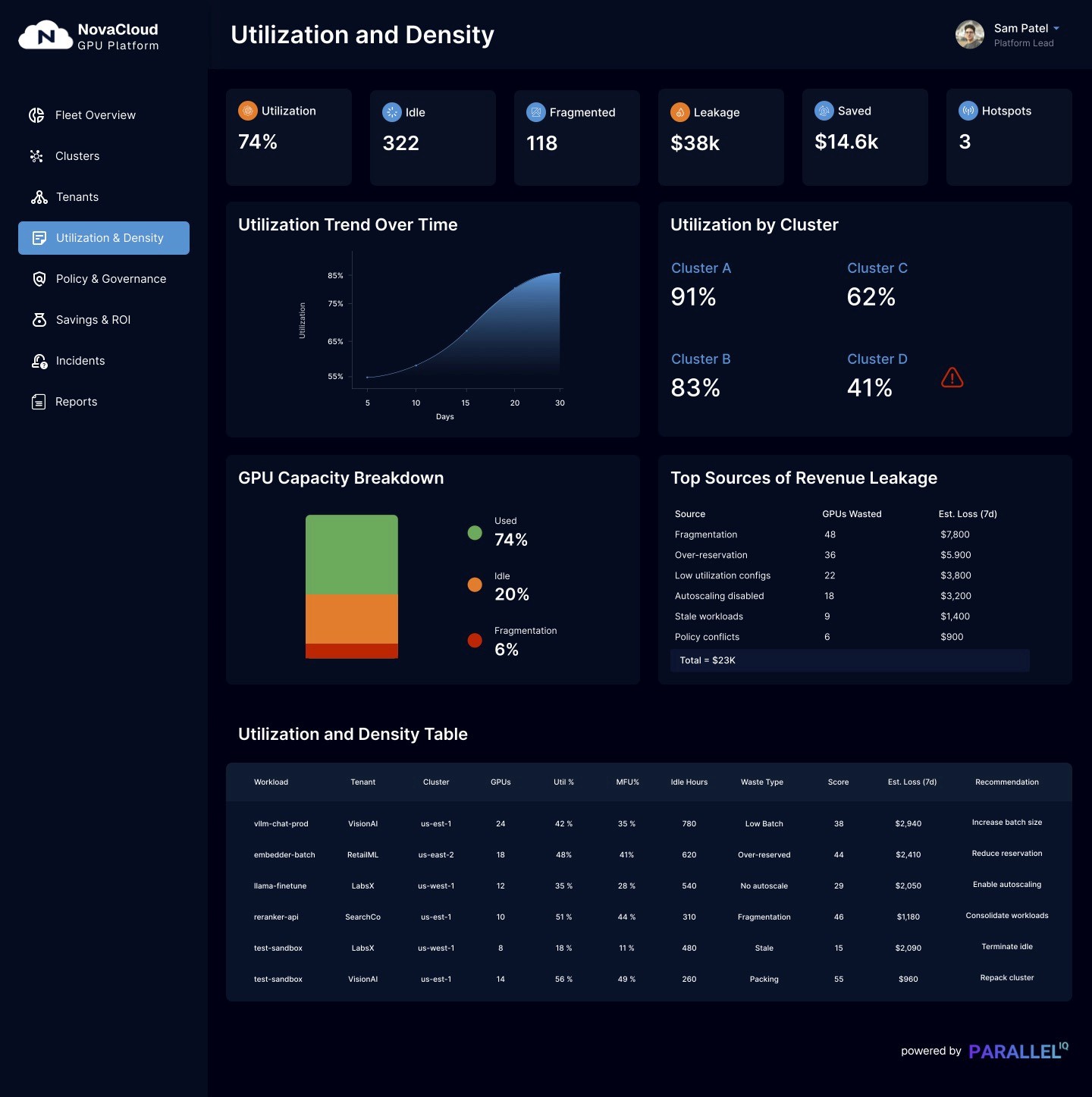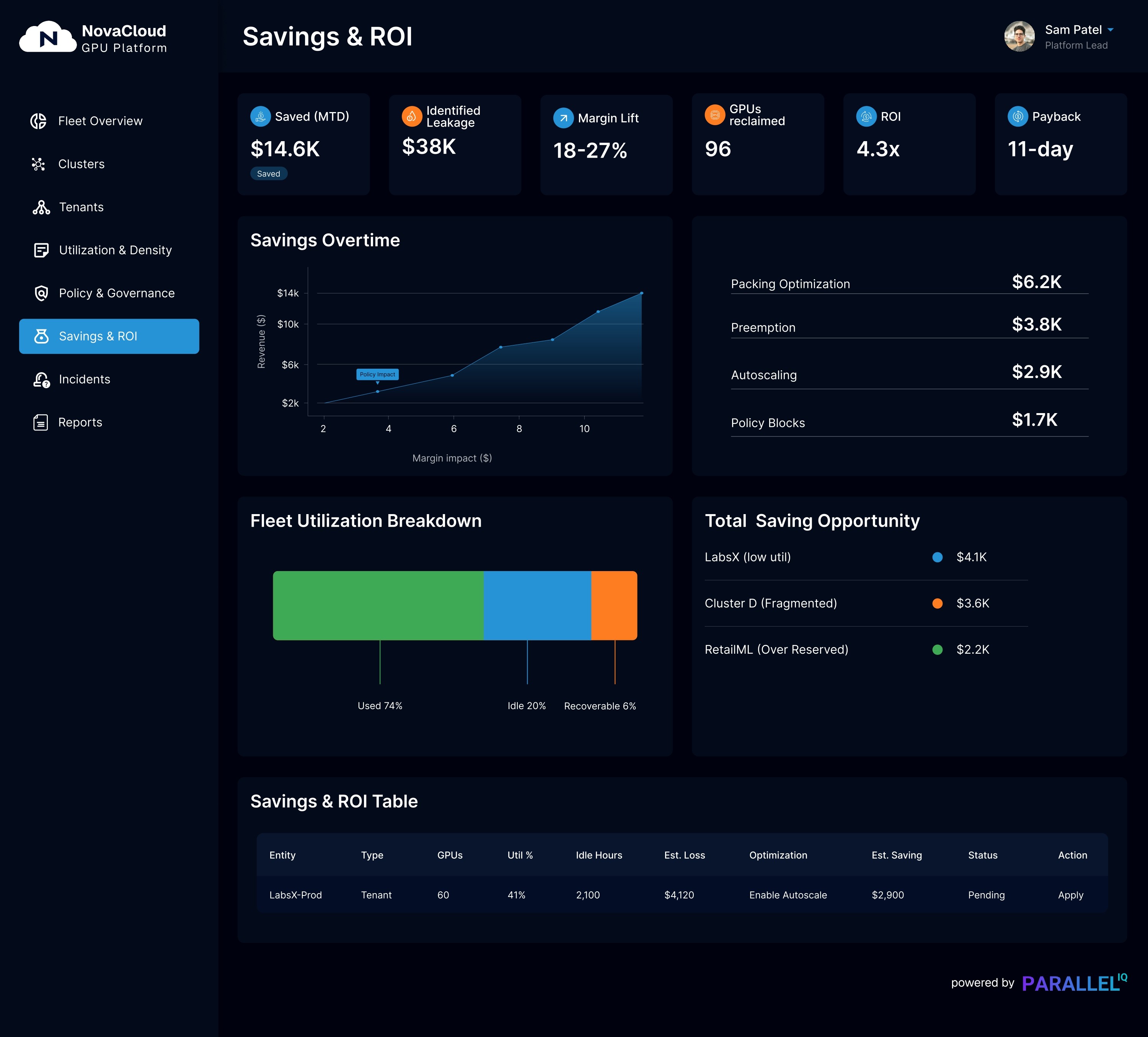
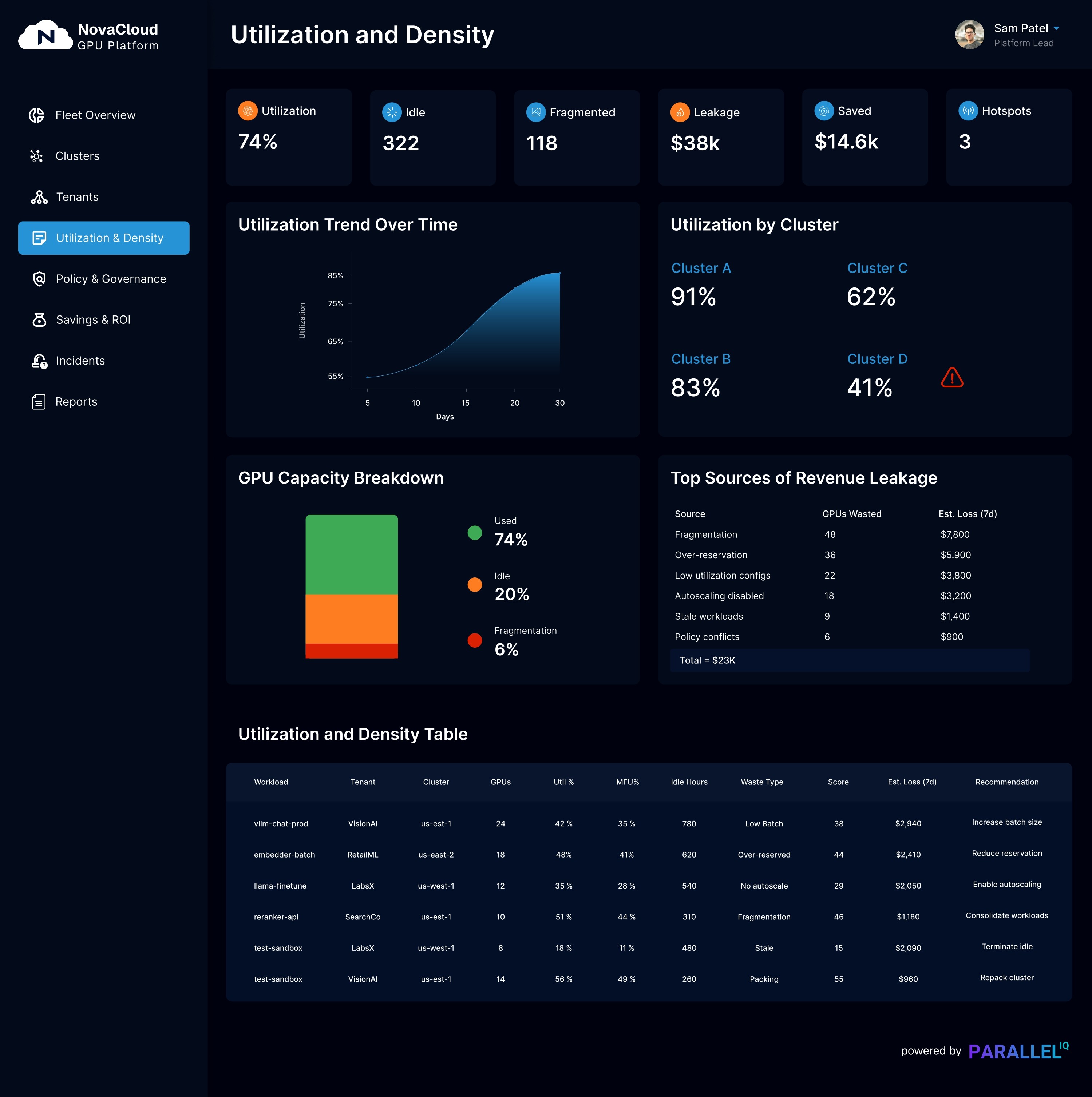













Control Plane Dashboard Gallery
Provider View
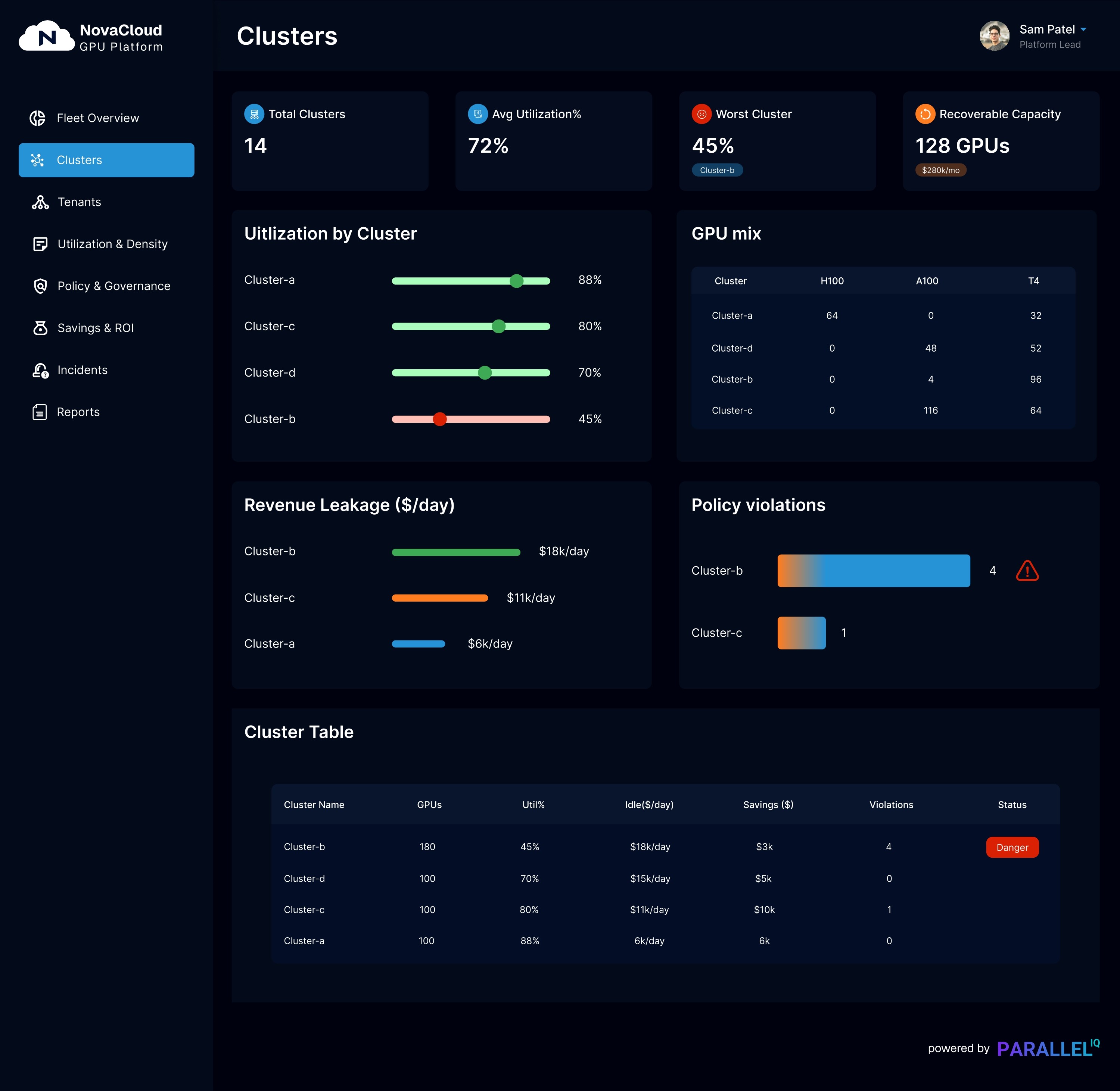


Tenant View
Why AI Infra Is Breaking?
AI infrastructure today wasn’t designed for the way modern models behave.
ParallelIQ addresses the three structural failures at the core of AI operations
Zero Visibility Into AI Workloads


GPUs Are Busy — But Not Productive
No Clarity on What's Actually Running

ParallelIQ gives ML and platform teams the visibility, context, and intelligence needed to run AI workloads efficiently at scale.

Model & Workload Discovery
Automatically identify every model, GPU, batch size, and runtime configuration across your cluster.

Real GPU Cost & Efficiency Mapping
Link throughput, memory behavior, and scaling patterns directly to GPU spend and efficiency.

Predictive Orchestration
Move beyond reactive autoscaling with orchestration that anticipates GPU demand before spikes occur.

Declarative Model Metadata (ModelSpec)
Give infrastructure a machine-readable description of model attributes, dependencies, and operational requirements.
Expert Services to Optimize Your AI Infrastructure
ParallelIQ pairs deep AI-runtime expertise with hands-on execution to help teams reduce waste, improve reliability, and scale with confidence.
Products
Core building blocks that bring visibility, control, and efficiency to AI infrastructure.
Open-Core
PIQC Introspect
Your cluster’s X-ray.
Complete model inventory
GPU and accelerator characteristics
AI workload detection
Static and runtime configuration insights
Private Beta
Predictive Orchestration
Orchestration built for ML — not microservices.
Predicts GPU demand ahead of spikes
Reduces cold-start and warm-up latency
Manages hot, warm, and cold GPU pools
Plans capacity with cost awareness
Open Schema
ModelSpec
A machine-readable contract for running models in production.
Model dependencies and pipeline context
GPU, memory, and runtime requirements
Latency and throughput SLOs
Security, compliance, and guardrails






Case Studies
Real results: lower costs, faster launches, longer runway.




The AI Infrastructure Journal
Deep dives into architecture, performance tuning, and operational excellence.