





Case study 1

Introduction: The AI Execution Gap — Why Infrastructure, Costs, and Drift Kill
Training modern AI models — especially large transformers — is massively resource-hungry. Companies invest millions in GPU clusters, yet studies and real-world audits show a common problem: utilization often sits far below 50%. The result? Cloud bills that executives can’t explain and infrastructure teams struggle to justify.
The problem isn’t the models — it’s the lack of visibility into GPU usage and the absence of policies that keep resources aligned with demand. This gap leads to wasted spend, unpredictable budgets, and slower ROI on AI investments.
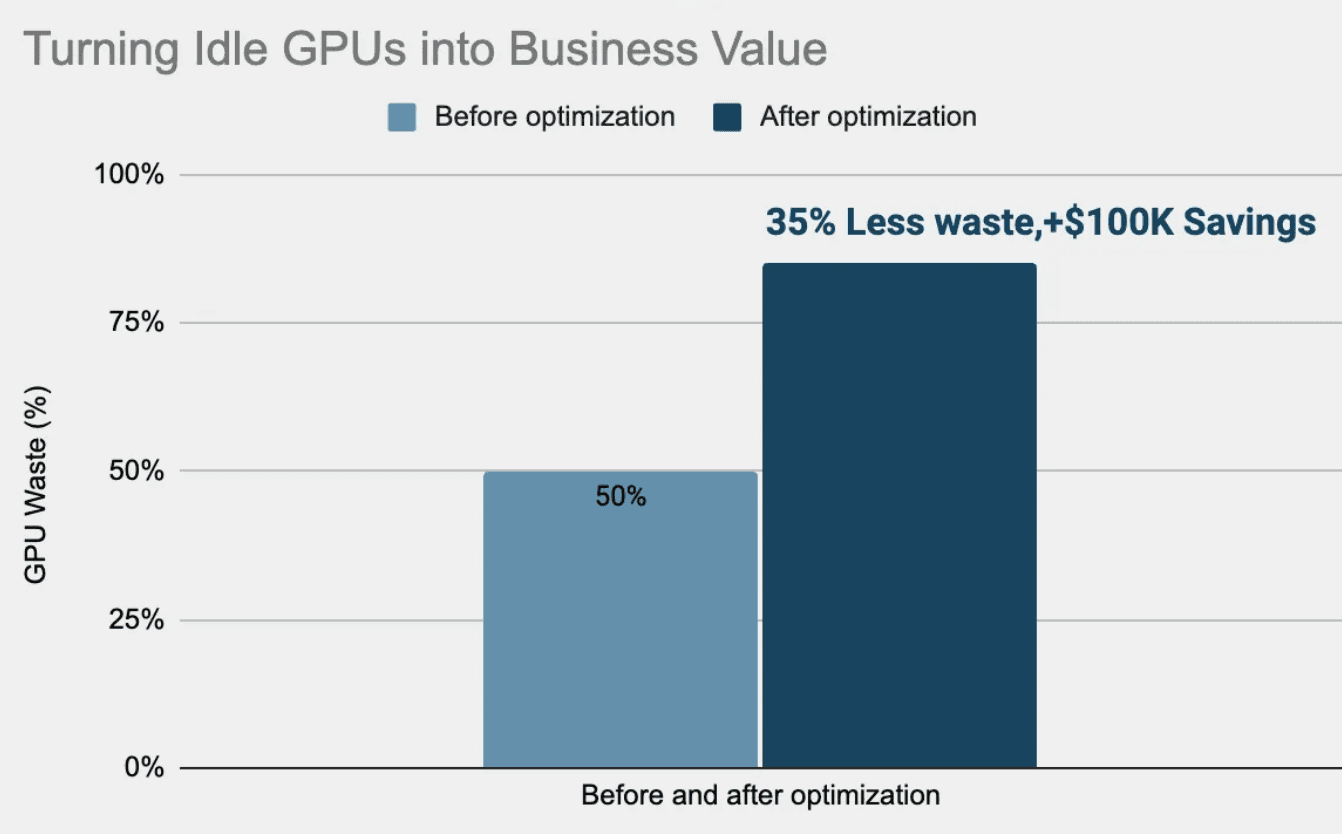
In this article, we’ll share a real-world case study where optimizing GPU utilization for training workloads delivered a 35% reduction in waste and six-figure annual savings — all while keeping model throughput stable.
The Challenge: GPU Waste, Latency Spikes, and Rising Cloud Costs
A client running large transformer models on Google Kubernetes Engine (GKE) was struggling with spiraling cloud costs. GPU utilization often sat below 60%, leaving expensive resources idle and draining budget without delivering results.
This case study draws from the prior work of one of our team members. The lessons learned are directly relevant to the grow-stage startups AI adoption challenges we see every day at ParallelIQ.
The Approach: Fixing AI Infrastructure with Monitoring and Optimization
In this case study, Kubecost was integrated with NVIDIA DCGM metrics to provide real-time visibility into GPU usage. This revealed patterns of underutilization and extended idle time. By implementing autoscaling policies and applying right-sizing strategies for GPU node pools, resource allocation was aligned with actual training demand.
The Results: Lower Training Costs, Stable Throughput, Higher ROI
35% reduction in GPU waste
Six-figure annual cost savings without sacrificing training throughput
More predictable cloud bills, making AI costs easier for executives to justify
Even advanced ML teams can’t afford underutilized GPUs. Cost monitoring + right-sizing can unlock massive savings while maintaining productivity — proving that observability directly drives ROI.
Lessons for Growth-Stage Startups: Closing the AI Execution Gap with Observability
For growth-stage organizations, the temptation is often to jump straight into building or buying models. But the reality is that most AI projects fail not because of weak algorithms, but because the execution breaks down — idle GPUs, runaway cloud costs, and models that silently drift away from reality.
The lesson is clear: don’t start with the model — start with observability. By instrumenting workloads across three pillars — performance, cost, and accuracy — companies gain the visibility to:
Detect stalls before they spiral into downtime.
Optimize GPU and cloud spend to protect budgets.
Catch drift early so models continue to deliver trustworthy predictions.
This shift is especially critical in company’s growth stage, where resources are constrained and executives demand measurable ROI. Without observability, every project carries high risk and unpredictable cost. With it, firms move closer to AI readiness — systems that can scale reliably, deliver results faster, and justify continued investment.
At ParallelIQ, this is our focus: helping growth-stage startups close the AI Execution Gap by building strong observability foundations. The outcome is simple but powerful — AI that’s not just possible, but practical and profitable.
Closing: Building AI-Ready Infrastructure for Sustainable ROI
At ParallelIQ, we help companies build AI observability stacks that catch hidden costs, performance stalls, and drift before they hurt the business. Don’t let your AI run blind — make it observable.
Audit your workloads. Measure GPU idle time. Invest in monitoring. That’s how you avoid the execution gap.
👉 Want to learn how observability can accelerate your AI execution?
[Schedule a call to discuss → here]
