


AI/ML Model Operations
The New AI Stack: Why Foundation Models Are Partnering, Not Competing, with Cloud Providers

Introduction — The Illusion of Competition
At first glance, it looks like cloud providers and foundation-model companies are on a collision course. Both are racing to power the AI revolution: hyperscalers control the compute, while model labs control the intelligence. It would be natural to think one will eventually replace the other.
But that’s not what’s happening. Beneath the surface, a new kind of collaboration is forming — one built not on competition but on complementarity. Model developers such as Anthropic, OpenAI, and Cohere aren’t trying to outbuild the clouds; they’re building on them.
This partnership model is quietly defining the new AI stack — where clouds provide the substrate of GPUs, compliance, and global reach, and foundation models provide the intelligence that makes all that infrastructure valuable.
The Old Model: Cloud-Native
The 2010s were defined by the cloud-native movement. Software companies moved from racks and data centers to managed compute on AWS, GCP, and Azure. Cloud providers monetized compute, storage, and networking, while startups layered innovation above them — selling SaaS subscriptions and developer APIs.
That architecture worked because the intelligence resided in code. Cloud services merely hosted and scaled that code. The economics were simple: you paid for compute, and your application logic ran deterministically on it.
But AI changes the equation. The “code” that drives modern applications is no longer written line by line — it’s learned. The new logic lives inside massive neural networks that are expensive to train, opaque to inspect, and adaptive at runtime.
The center of gravity has shifted from cloud infrastructure to model intelligence — and the economic boundaries are being redrawn.
The Shift: From Cloud-Native to Model-Native
In this new paradigm, we see the emergence of a layered ecosystem:
Hardware Layer: Specialized accelerators (H100, MI300, Gaudi, TPUs) provide raw compute.
Cloud Layer: Hyperscalers manage GPU clusters, networking, and orchestration.
Model Layer: Foundation-model companies train, align, and update large-scale models like Claude, GPT-4, and Mistral 8×7B.
Application Layer: Enterprises and startups build copilots, agents, and RAG systems powered by these models.
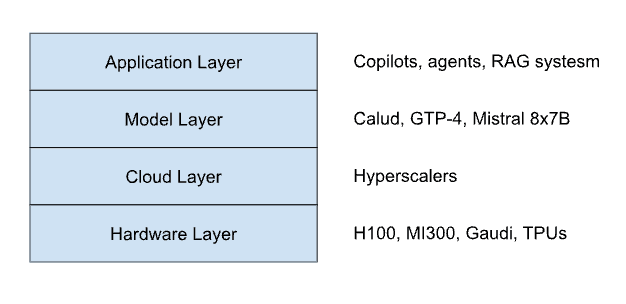
Each layer depends on the one below it. The model layer cannot exist without the scale and compliance of the cloud; the cloud, in turn, gains differentiation by hosting the world’s most capable models.
As one Anthropic executive put it privately:
“Clouds own the metal. Models own the intelligence. The future belongs to whoever orchestrates the two — those who can make intelligence run efficiently on infrastructure.”
Case in Point: Claude and AWS Bedrock
Anthropic’s partnership with Amazon Web Services is the clearest example of this new equilibrium. Instead of building its own datacenter empire, Anthropic integrated Claude directly into Amazon Bedrock, AWS’s managed foundation-model platform.
How it works:
Anthropic maintains the model weights, safety layers, fine-tuning pipeline, and version control (Claude 1 → 2 → 3 → 3.5).
AWS provides the GPU infrastructure, global networking, billing, and enterprise compliance stack.
Customers access Claude via the Bedrock API — often from within their own VPC using PrivateLink — ensuring data never leaves the AWS boundary.
This structure gives every enterprise on AWS instant access to Claude models with the same compliance guarantees as their existing workloads. Anthropic can focus on model safety and innovation, while AWS handles distribution and uptime at hyperscale.
In short: Anthropic didn’t build a competing cloud — it plugged intelligence into one.
A Broader Pattern: The Model–Cloud Symbiosis
This is not a one-off. It’s the new playbook for the AI ecosystem:
Press enter or click to view image in full size

Each partnership binds the intelligence layer (models) with the infrastructure layer (clouds). The relationship is symbiotic:
Model companies need hyperscalers’ global GPU fleets, compliance regimes, and customer reach.
Cloud providers need foundation models to make their compute and APIs sticky, differentiated, and monetizable.
Rather than fighting for dominance, they are mutually entangled — a vertical handshake at the heart of the AI economy.
Where Open Model Hubs Fit: The Role of Hugging Face
While Anthropic, OpenAI, and Cohere represent the proprietary side of the model–cloud symbiosis, there’s a second axis of innovation shaping the new AI stack: the open-source ecosystem, led by platforms like Hugging Face.
Hugging Face has become the de facto model hub for the open-AI community. It hosts millions of models, datasets, and demos (“Spaces”), enabling anyone — from researchers to enterprises — to discover, fine-tune, and deploy AI systems without going through a proprietary API. Its libraries (Transformers, Diffusers, PEFT, Datasets) abstract away the complexity of model integration, creating a shared language for developers across frameworks and hardware.
In the broader architecture, Hugging Face occupies a hybrid position between the model and middleware layers:
It distributes open-weight models such as Llama 3, Mistral 7B, and Falcon, bridging the gap between academic innovation and enterprise adoption.
It provides tooling and serving infrastructure — from Inference Endpoints to managed Spaces — that let companies deploy models on their own cloud of choice.
It partners with hyperscalers like AWS, Azure, and GCP to run hosted inference, aligning with the same “partnership-not-competition” principle that underpins Anthropic’s Claude on Bedrock.
For enterprises, this creates choice. They can use Claude or GPT-4 through managed APIs, or select open models through Hugging Face and host them within their private environments. That flexibility introduces healthy competition while reinforcing — not weakening — the cloud ecosystem. Each major cloud now integrates Hugging Face natively, allowing customers to pull models directly into their VPCs with full compliance and monitoring.
If the proprietary model–cloud partnerships represent the closed, curated intelligence layer, Hugging Face represents the open, collaborative intelligence layer. Together they complete the picture: an AI stack that is both vertically integrated and horizontally open.
In the new AI economy, innovation isn’t centralized — it’s federated. Cloud providers, model labs, and open hubs like Hugging Face are co-architects of the same system.
Why They Need Each Other
Foundation-model labs rely on clouds for:
Compute capacity: Thousands of H100s per training run.
Regional availability: Legal and data-sovereignty constraints.
Reliability & redundancy: SLA-level uptime.
Enterprise onboarding: Integrations with IAM, billing, and procurement.
Clouds rely on model labs for:
Differentiation: Every hyperscaler sells GPUs — only a few offer GPT-4 or Claude.
Ecosystem lock-in: Customers building on Bedrock or Azure stay there for inference.
Revenue density: Model APIs drive high-margin compute utilization.
This interdependence forms the economic backbone of the foundation-model era. It’s no longer about who “owns” the customer; it’s about who can make AI useful at scale.
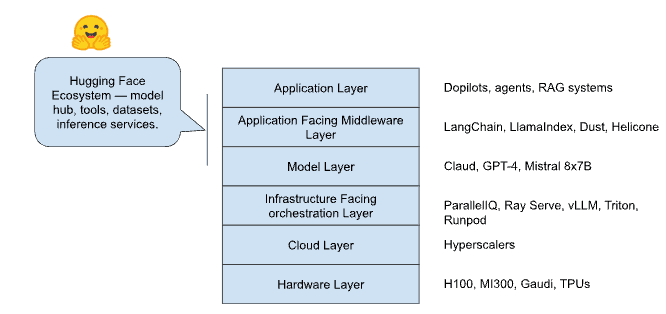
The New Stack: Layers of the AI Economy
Visualize the modern AI economy as a six-layer system — with two distinct kinds of “middleware” that connect intelligence to infrastructure in opposite directions:
Hardware Layer: NVIDIA, AMD, Intel — provide acceleration.
Cloud Layer: AWS, Azure, GCP, Oracle — deliver scalability, networking, and compliance.
Infrastructure-Facing Orchestration Layer: ParallelIQ, Ray Serve, vLLM, Triton, Runpod — align models with infrastructure.
- Focus: predictive scaling, TTFT/TPS optimization, GPU utilization, cost orchestration, observability.
- Focus: predictive scaling, TTFT/TPS optimization, GPU utilization, cost orchestration, observability.Model Layer: Anthropic, OpenAI, Mistral, Cohere — produce intelligence.
Application-Facing Middleware Layer: LangChain, LlamaIndex, Dust, Helicone — help developers use models effectively.
- Focus: prompt assembly, RAG pipelines, chaining, agent control, evaluation harnesses.
- Boundary: Application ↔ Model — improving how applications interface with intelligence.Application Layer: Enterprises, vertical AI systems, copilots, and agents — create business value.
Each layer is monetized differently — per GPU-hour, per token, or per seat — but all are tightly coupled.
The key insight: orchestration is bifurcated.
Above the models, orchestration improves how we talk to intelligence.
Below the models, orchestration improves how intelligence runs on hardware.
ParallelIQ belongs firmly to the latter: it’s the bridge between model intelligence and cloud infrastructure, ensuring the right resources are provisioned before the workload arrives — predictive, efficient, and compliant.
Each layer is monetized differently — per GPU-hour, per token, per seat — but all are tightly coupled. The clouds no longer sit beneath the models; they interlock with them.
The Emerging Frontier: Private AI and Hybrid Inference
As enterprise adoption grows, privacy and governance become the next battleground. Companies want AI that’s both powerful and contained. Expect to see:
Private-cloud instances of Claude, GPT-4, and Mistral hosted within enterprise VPCs.
Hybrid inference pipelines where static model components are cached on-prem, while dynamic inference runs in the cloud.
AI observability and compliance frameworks that bridge the gap between model usage and corporate governance.
This evolution mirrors the early cloud journey: from public APIs → private endpoints → hybrid deployments. The new AI stack will follow the same curve — but faster.
Beyond LLMs: The Broader Foundation-Model Pattern
Although this discussion focuses on large language models, the same dynamics apply across other foundation models — vision, multimodal, speech, and scientific domains alike.
Models such as Stable Diffusion, Runway Gen-2, Whisper, and AlphaFold depend on the same fundamental relationship between model developers and cloud infrastructure: massive GPU clusters for training, compliance-ready endpoints for serving, and enterprise-grade SLAs for integration.
LLMs simply expose this dependency most clearly. They’re the most visible, compute-intensive, and commercially transformative layer of the foundation-model stack — the part of the iceberg above the surface.
Beneath it lies an even larger and more diverse ecosystem of models that will follow the same trajectory of partnership, not competition, as AI matures.
Conclusion — The Compact Between Intelligence and Infrastructure
The future of AI isn’t a battle between model labs and clouds. It’s a compact between intelligence and infrastructure.
Foundation-model companies bring innovation and reasoning capability. Cloud providers bring scale, reliability, and trust. Together, they’re creating a new architecture for computing — one where the model becomes the new operating system and the cloud becomes its runtime.
The new AI stack isn’t cloud-native or model-native. It’s partnership-native.
Orchestrating the Future
As models and clouds converge, orchestration becomes the control plane of the AI economy. At ParallelIQ, we help companies bridge that gap — making every GPU hour count through predictive scaling, observability, and cost-aware optimization.
The next generation of AI infrastructure won’t be built by bigger budgets — but by smarter orchestration.



