


AI/ML Model Operations
The Missing Control Plane for GPU Platforms: Policy as Code, Not Just Schedulers

GPU platforms have become the backbone of modern AI. Startups and enterprises now deploy large language models, embedding pipelines, and inference services on clusters of high-end GPUs. Yet despite all this sophistication, most GPU platforms today are still operated using a fragile mix of YAML, scripts, tickets, and human judgment.
What’s missing is not a better scheduler. What’s missing is a real control plane.
GPUs Are Being Sold as Products, But Operated Like Infrastructure
When customers buy GPU capacity, they are not buying machines. They are buying product guarantees such as:
entitlements (“I paid for 4 H100s”)
SLAs (“low latency, no preemption”)
isolation (“no noisy neighbors”)
compliance (“EU-only, dedicated hardware”)
lifecycle semantics (“scale up, scale down, offboard cleanly”)
But today, those guarantees live in contracts, internal runbooks, tribal knowledge and best-effort operational discipline. They are not encoded into the system. That gap is why GPU platforms struggle with:
noisy neighbors
broken SLAs
unpredictable onboarding
chaotic scaling
compliance gaps
constant manual firefighting
A Control Plane Is Not an Orchestrator
Most GPU platforms assume their “control plane” is Kubernetes, Slurm, or a scheduler. It isn’t. Those systems decide how workloads run. A real control plane decides:
who is allowed to run what
where workloads may be placed
how much capacity a tenant is entitled to
whether a request must be approved
what isolation rules apply
what happens on failure
how data must be retained or destroyed
Those are product and governance decisions, not scheduling decisions.
The 4-Lane Blueprint for a GPUaaS Control Plane
To make this concrete, I built a BPM-style swimlane blueprint that separates responsibilities into four distinct layers:
Press enter or click to view image in full size
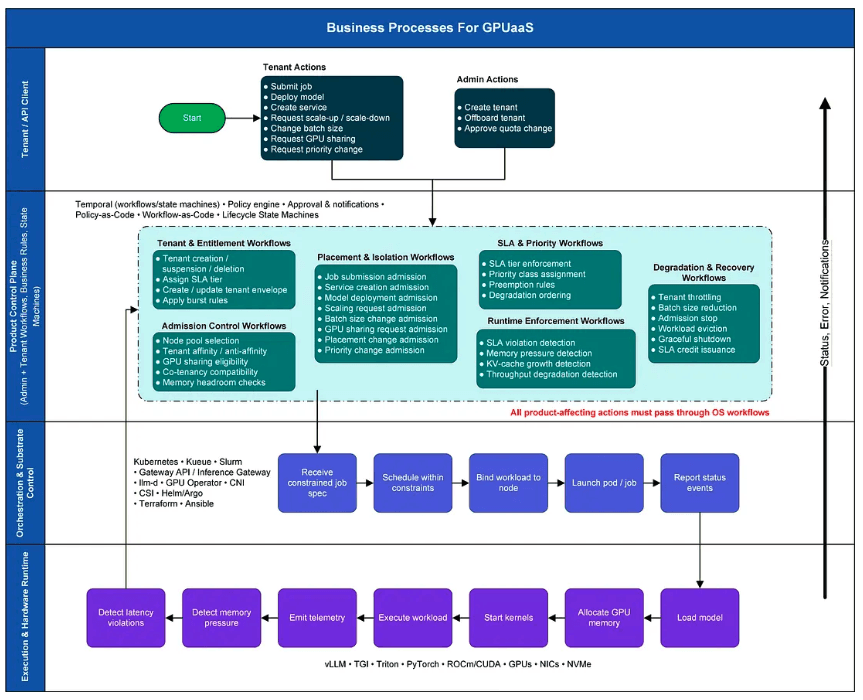
Lane 1 — Northbound Product API / UI
Tenant and admin actions such as:
create tenant
deploy model
request scale-up
change batch size
request GPU sharing
update quotas
offboard tenant
These are product-level intents.
Lane 2 — Product Control Plane
Policy-as-Code • Workflow-as-Code • Lifecycle State Machines
This is the missing layer. It owns:
tenant entitlements and quotas
SLA tiers and isolation rules
admission control
placement policies
privacy and compliance rules
degradation and preemption policies
onboarding and offboarding workflows
Crucially, these are not scripts. They are:
declarative policies
versioned rules
durable workflows
explicit state machines
This is where Policy as Code actually lives.
Lane 3 — Orchestration & Substrate Control
This layer turns control-plane decisions into reality:
Kubernetes
Slurm / Kueue
Gateway API / inference gateways
GPU operators
Helm / Argo CD
Terraform / Ansible
CNI / CSI
It does not decide policy. It only realizes policy.
Lane 4 — Execution & Hardware
Where work actually happens:
vLLM, Triton, TGI
PyTorch
ROCm / CUDA
GPUs
NICs
NVMe
This is the physical reality layer.
Policy as Code: The Core of the Control Plane
The key idea is that GPU platforms need a policy-as-code control plane, not just a scheduler. Instead of writing documents like:
“Enterprise tenants must run on dedicated GPUs in EU clusters and cannot be preempted.”
You encode:
# Example: tenantpolicy-as-code configuration tenant: tier: enterprise isolation: dedicated data_residency: eu-only allow_preemption: false allow_gpu_sharing: false
# Example: tenantpolicy-as-code configuration tenant: tier: enterprise isolation: dedicated data_residency: eu-only allow_preemption: false allow_gpu_sharing: false
# Example: tenantpolicy-as-code configuration tenant: tier: enterprise isolation: dedicated data_residency: eu-only allow_preemption: false allow_gpu_sharing: false
And the control plane enforces it by:
rejecting invalid requests
constraining placement
selecting eligible clusters
configuring schedulers
applying isolation rules
blocking unsafe actions
This is exactly how hyperscalers work internally. GPU platforms today simply don’t have this layer.
Workflows, Not Scripts
A real control plane is workflow-driven. Examples:
tenant onboarding
quota increases
SLA upgrades
capacity exhaustion
incident response
offboarding and data destruction
These are not bash scripts. They are:
long-running processes
with approvals
retries
compensations
audit trails
explicit state transitions
That’s why Lane 2 must be implemented as: Policy-as-Code + Workflow-as-Code + Durable State Machines
Why Is This Important
Without this layer, GPU platforms are forced to operate like fragile infrastructure projects instead of reliable products. That’s why we see:
unpredictable performance
noisy neighbors
broken SLAs
chaotic onboarding
manual firefighting
compliance gaps
A programmable control plane fixes this by turning:
product promises
governance rules
lifecycle semantics
into machine-enforceable reality.
Closing Thought
Kubernetes orchestrates containers. Slurm schedules jobs. vLLM runs inference. Llm-d routes and scales inference traffic. But none of those systems know what a tenant, an SLA, or a privacy tier is. That knowledge belongs in a real control plane. And that control plane must be built on policy as code, not scripts.
Closing
I’m open-sourcing parts of this control-plane blueprint and documenting the workflows, policies, and lifecycle semantics behind it. You can find the blueprint here.
If you’re building a GPU platform or GPUaaS product and wrestling with multi-tenancy, SLAs, or onboarding reliability, I’d love to compare notes.
GPU platforms have become the backbone of modern AI. Startups and enterprises now deploy large language models, embedding pipelines, and inference services on clusters of high-end GPUs. Yet despite all this sophistication, most GPU platforms today are still operated using a fragile mix of YAML, scripts, tickets, and human judgment.
What’s missing is not a better scheduler. What’s missing is a real control plane.
GPUs Are Being Sold as Products, But Operated Like Infrastructure
When customers buy GPU capacity, they are not buying machines. They are buying product guarantees such as:
entitlements (“I paid for 4 H100s”)
SLAs (“low latency, no preemption”)
isolation (“no noisy neighbors”)
compliance (“EU-only, dedicated hardware”)
lifecycle semantics (“scale up, scale down, offboard cleanly”)
But today, those guarantees live in contracts, internal runbooks, tribal knowledge and best-effort operational discipline. They are not encoded into the system. That gap is why GPU platforms struggle with:
noisy neighbors
broken SLAs
unpredictable onboarding
chaotic scaling
compliance gaps
constant manual firefighting
A Control Plane Is Not an Orchestrator
Most GPU platforms assume their “control plane” is Kubernetes, Slurm, or a scheduler. It isn’t. Those systems decide how workloads run. A real control plane decides:
who is allowed to run what
where workloads may be placed
how much capacity a tenant is entitled to
whether a request must be approved
what isolation rules apply
what happens on failure
how data must be retained or destroyed
Those are product and governance decisions, not scheduling decisions.
The 4-Lane Blueprint for a GPUaaS Control Plane
To make this concrete, I built a BPM-style swimlane blueprint that separates responsibilities into four distinct layers:
Press enter or click to view image in full size
Lane 1 — Northbound Product API / UI
Tenant and admin actions such as:
create tenant
deploy model
request scale-up
change batch size
request GPU sharing
update quotas
offboard tenant
These are product-level intents.
Lane 2 — Product Control Plane
Policy-as-Code • Workflow-as-Code • Lifecycle State Machines
This is the missing layer. It owns:
tenant entitlements and quotas
SLA tiers and isolation rules
admission control
placement policies
privacy and compliance rules
degradation and preemption policies
onboarding and offboarding workflows
Crucially, these are not scripts. They are:
declarative policies
versioned rules
durable workflows
explicit state machines
This is where Policy as Code actually lives.
Lane 3 — Orchestration & Substrate Control
This layer turns control-plane decisions into reality:
Kubernetes
Slurm / Kueue
Gateway API / inference gateways
GPU operators
Helm / Argo CD
Terraform / Ansible
CNI / CSI
It does not decide policy. It only realizes policy.
Lane 4 — Execution & Hardware
Where work actually happens:
vLLM, Triton, TGI
PyTorch
ROCm / CUDA
GPUs
NICs
NVMe
This is the physical reality layer.
Policy as Code: The Core of the Control Plane
The key idea is that GPU platforms need a policy-as-code control plane, not just a scheduler. Instead of writing documents like:
“Enterprise tenants must run on dedicated GPUs in EU clusters and cannot be preempted.”
You encode:
# Example: tenantpolicy-as-code configuration tenant: tier: enterprise isolation: dedicated data_residency: eu-only allow_preemption: false allow_gpu_sharing: false
And the control plane enforces it by:
rejecting invalid requests
constraining placement
selecting eligible clusters
configuring schedulers
applying isolation rules
blocking unsafe actions
This is exactly how hyperscalers work internally. GPU platforms today simply don’t have this layer.
Workflows, Not Scripts
A real control plane is workflow-driven. Examples:
tenant onboarding
quota increases
SLA upgrades
capacity exhaustion
incident response
offboarding and data destruction
These are not bash scripts. They are:
long-running processes
with approvals
retries
compensations
audit trails
explicit state transitions
That’s why Lane 2 must be implemented as: Policy-as-Code + Workflow-as-Code + Durable State Machines
Why Is This Important
Without this layer, GPU platforms are forced to operate like fragile infrastructure projects instead of reliable products. That’s why we see:
unpredictable performance
noisy neighbors
broken SLAs
chaotic onboarding
manual firefighting
compliance gaps
A programmable control plane fixes this by turning:
product promises
governance rules
lifecycle semantics
into machine-enforceable reality.
Closing Thought
Kubernetes orchestrates containers. Slurm schedules jobs. vLLM runs inference. Llm-d routes and scales inference traffic. But none of those systems know what a tenant, an SLA, or a privacy tier is. That knowledge belongs in a real control plane. And that control plane must be built on policy as code, not scripts.
Closing
I’m open-sourcing parts of this control-plane blueprint and documenting the workflows, policies, and lifecycle semantics behind it. You can find the blueprint here.
If you’re building a GPU platform or GPUaaS product and wrestling with multi-tenancy, SLAs, or onboarding reliability, I’d love to compare notes.



Don’t let performance bottlenecks slow you down. Optimize your stack and accelerate your AI outcomes.
Don’t let performance bottlenecks slow you down. Optimize your stack and accelerate your AI outcomes.
Don’t let performance bottlenecks slow you down. Optimize your stack and accelerate your AI outcomes.
Don’t let performance bottlenecks slow you down. Optimize your stack and accelerate your AI outcomes.

Services
© 2025 ParallelIQ. All rights reserved.
Services
© 2025 ParallelIQ. All rights reserved.
Services
© 2025 ParallelIQ. All rights reserved.