


AI/ML Model Operations
The Invisible AI Deployment Footprint: Why MLOps Teams Lose Visibility as They Scale

If you ask most AI teams how many models they’re training, they’ll give you a clean answer. If you ask how many models they’re serving in production, across every cloud and cluster…. you’ll usually get a long pause.
And it’s not because the engineers don’t care. It’s because visibility breaks down as companies grow.
Whether it’s a Series B startup operating multiple inference clusters or a mid-market company scaling LLM-based products across regions and GPU clouds, the same pattern emerges:
The larger the organization, the more invisible the model footprint becomes.
Let’s unpack why this happens — and why it becomes a costly problem if left unaddressed.
The Rise of Multi-Cloud AI Infrastructure
Five years ago, “multi-cloud AI” was exotic. Today it’s reality.
Teams now routinely spread workloads across:
AWS for core production
GCP for specialized training jobs
CoreWeave / Nebius for cheaper or higher-performance GPUs
Azure for enterprise compliance requirements
Baseten / Modal / Anyscale for rapid prototyping
Even early-stage startups do this unintentionally. They run:
a staging cluster in AWS,
a prod cluster in GCP,
a cheap backup endpoint in a GPU cloud,
and an experiment in someone’s laptop-powered minikube.
None of this is wrong. But it creates one big issue:
No single place shows all deployed models across all clouds.
Kubernetes Makes This Problem Worse (and Better)
Most serious inference workloads end up on Kubernetes:
vLLM deployments
TGI/TensorRT/Triton servers
embedding and reranker services
RAG pipelines with chunkers + retrievers
Teams deploy them across:
multiple clusters
multiple namespaces
multiple regions
multiple autoscaling groups
multiple GPU instance types
Kubernetes brings power and flexibility — but also sprawl. Because Kubernetes doesn’t care that a Deployment is “a model,” it’s just another object. It won’t tell you:
how many replicas exist across the entire company
whether prod and EU-prod run the same version
which GPU types are used in which clusters
whether a staging workload accidentally scaled to 16 replicas
whether an old endpoint is still secretly consuming $3K/month
which team actually owns each model
This leads to the next problem…
Ownership Fragmentation = Financial Confusion
As AI adoption spreads inside a company, different groups quietly deploy models:
Search team deploys embeddings
Chat team deploys a 7B fine-tune
Risk team deploys fraud models
Enterprise team deploys a proprietary LLM
Each region runs its own version
SRE deploys emergency backup replicas after an outage
And then Finance asks:
“Which teams are responsible for our GPU bill this month?”
No one has a clean answer. Most companies do not have:
a model governance system
a model deployment inventory
a multi-cluster footprint registry
a cloud-wide model tracking mechanism
or any standardized way to describe what is actually running
MLflow registries don’t capture deployments. Monitoring systems track prediction logs, not deployments. Kubernetes manifests describe intent, not current state.
So inevitably…
Finance ends up paying for models no one knew were still running.
The Symptom: Cost Sprawl That Outpaces Growth
Here’s the uncomfortable truth: Most companies deploying LLMs waste between 20–40% of their inference spend.
Why?
1. Duplicate deployments
Prod in us-west-2
Prod in eu-central-1
Backup prod in CoreWeave
Shadow prod in Azure
All using expensive GPUs.
2. Wrong GPU for the job
A10G would suffice, but an A100/H100 is running the workload.
3. Autoscaling misconfigurations
A staging namespace still has autoscaling enabled.
4. Canary environments that never got turned off
A/B experiments become permanent by accident.
5. Forgotten endpoints
Old product versions still burning GPU hours.
In AI, cost is proportional to footprint, and footprint expands invisibly.
The Risk: Operational Drift Across Clouds and Regions
Cost isn’t the only problem.
A more dangerous issue is drift:
US region runs model v1.3
EU region still running v1.1
Backup region runs a custom fine-tune
Experiments use different quantization settings
GPUs differ — A10G vs A100 vs H100 vs L40S
When an outage hits, teams suddenly realize:
“The backup environment does NOT match production.”
This causes:
unpredictable failovers
inconsistent latency
degraded accuracy
failures during traffic shifts
compliance violations (EU vs US data handling)
Drift is invisible until it creates an incident.
Why This Happens: There Is No ‘Model Footprint Map’
The root cause is surprisingly simple:
We have model registries.
We have monitoring dashboards.
We have tracing, logging, and autoscaling.
But we do NOT have a way to map where models are deployed.
There is no standard artifact like:
“list of all inference workloads”
“GPU usage per model”
“replicas per environment”
“per-model cloud footprint”
“cross-region version comparison”
“ownership & cost center registry”
This gap means companies fly blind. As they scale, this blindness becomes expensive.
The Opportunity: A Unified Business ModelSpec
Imagine if every deployed model — regardless of cloud provider — had a single standard description:
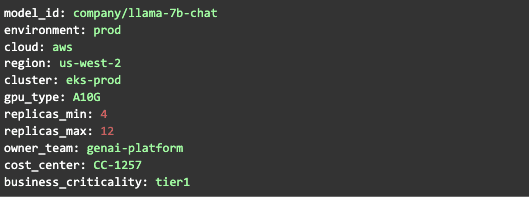
Imagine this existed:
for every region,
every cluster,
every cloud,
every deployment,
automatically,
with drift detection and ownership attribution.
This would give:
For CFOs
Cost transparency
Cost-center allocation
GPU budget governance
QBR-ready insights
For Heads of MLOps
Unified model inventory
Multi-cloud visibility
Version and replication drift detection
Easier platform standardization
For SRE
Region-to-region failover readiness
Accurate emergency response maps
For Engineering Leadership
Strategic clarity on AI investment
This is what’s missing today.
Why Companies Should Think About This Now
As soon as a company deploys:
more than 5 models,
across multiple clusters,
or across more than one cloud,
this footprint visibility problem becomes real.
Most companies don’t feel the pain until it’s too late:
GPU bills exploding
inconsistent model behavior across regions
surprise replicas consuming expensive instances
compliance or governance gaps
lack of clear ownership
inability to answer basic operational questions
The earlier companies adopt model footprint tracking, the smoother their scale will be.
Closing Thoughts: You Can’t Govern What You Can’t See
AI infrastructure is becoming the new cloud infrastructure: large, distributed, multi-cloud, and increasingly fragmented. If we learned anything from DevOps in the 2010s, it’s this:
Visibility precedes governance.
Governance precedes optimization.
Optimization precedes cost reduction.
AI teams today are in the visibility stage — and the industry lacks the tooling to support it.
Over the coming months, I’ll be sharing more on:
how companies can build model footprint maps
how to standardize Business ModelSpecs
how to detect multi-cloud drift
how to align GPU consumption with business value
and how platform teams can get ahead of runaway inference complexity
The model footprint problem is real, growing, and solvable — but only if we acknowledge it early.



