


AI/ML Model Operations
The 3 Core Pillars of AI/ML Monitoring: Performance, Cost, and Accuracy

Why Monitoring Matters: The Hidden Risks in AI/ML Systems
“AI doesn’t fail because of math — it fails because no one is watching.”
Traditional software tends to fail loudly — a server crashes, a database times out, an application throws an error. These incidents are disruptive, but they’re usually obvious and quickly addressed. AI workloads are different. They fail silently — and the cost of missing those failures is measured not just in downtime, but in lost revenue and wasted spend.
A recommendation engine that drifts may continue serving results, but click-through rates and conversions quietly decline. A fraud detection model that lags at P99 latency may miss critical cases, translating directly into financial losses. A GPU cluster running at 30% utilization still shows “healthy” in dashboards, but it’s billing at 100% — burning budget that delivers no value.
These aren’t algorithmic problems — they’re execution and monitoring gaps. Without observability, you don’t just lose technical performance, you lose business momentum: slower revenue, higher costs, weaker trust.
That’s why AI needs more than uptime checks. To deliver real business value, systems must be observable across three critical pillars:
Performance — are we serving fast enough to capture revenue opportunities?
Cost — are we running efficiently enough to justify the spend?
Accuracy — are we making predictions reliable enough to support decisions?
Together, these determine whether AI investments generate ROI — or quietly erode it.
Pillar 1: Serving Performance — Latency, Throughput, and User Experience
Press enter or click to view image in full size

Key Question: Is the model meeting latency and throughput requirements?
When a model goes into production, it’s no longer just a research artifact — it becomes part of the business’ real-time workflows. That means it must consistently deliver predictions within strict time and reliability bounds. This is where service-level agreements (SLAs) and service-level objectives (SLOs) come into play.
Focus: Performance monitoring ensures compliance with metrics like P95/P99 latency, error rates, and uptime.
Latency: While the average (P50) might look fine, the tail latencies (P95/P99) often make or break user experience. A fraud detection model that responds in 200ms for most requests but spikes to 2s for 5% of transactions exposes millions in risk.
Throughput: Can the system handle peak load during traffic surges (e.g., Black Friday for e-commerce, or payroll cutoffs in fintech)?
Uptime: Even short outages can directly translate into revenue loss or reputational damage.
Tools: Engineering teams typically rely on observability stacks like Prometheus and Grafana for time-series metrics, OpenTelemetry for tracing, and APM platforms like Datadog or New Relic for end-to-end performance monitoring. Together, these provide real-time visibility into whether inference workloads are hitting their performance SLOs.
Why it matters: Unlike training stalls, which mostly waste infrastructure, inference stalls hit customers immediately.
A recommendation engine with spiking latency means abandoned shopping carts.
A fraud detection model that lags costs banks millions in missed or delayed interventions.
A voice assistant that stutters at P99 creates a broken user experience that drives users away.
Pillar 2: Cost Monitoring — Cloud Spend, GPU Utilization, and Efficiency
Press enter or click to view image in full size

Key Question: What is this workload costing us, and is it efficient?
AI infrastructure isn’t just complex — it’s expensive. High-performance GPUs, CPUs, networking, and cloud services can run into millions of dollars annually. Without visibility into how these resources are being used, organizations risk building AI systems that look impressive but burn through budgets with little return.
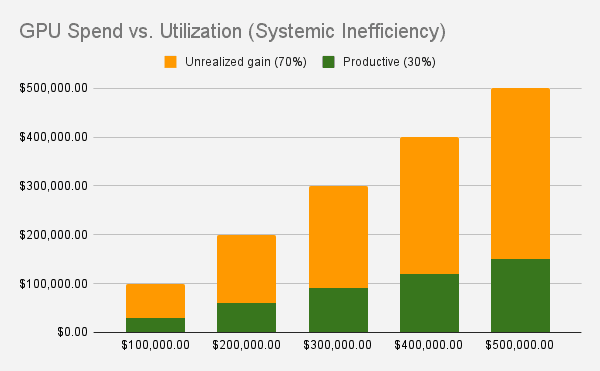
Focus: Cost monitoring zeroes in on:
GPU/CPU utilization: Are expensive accelerators sitting idle? A GPU running at 30% utilization is effectively wasting 70% of its cost.
Per-job/per-team breakdowns: Which projects or teams are driving consumption? This transparency allows leaders to tie spend to business value.
Idle resources: Clusters provisioned for “peak demand” often sit underused during normal operation, silently bleeding budget.
Tools: Solutions like Kubecost, cloud-native cost explorers, and FinOps dashboards give engineering and finance teams the shared visibility they need. They track real-time and historical spend, attribute costs by namespace or project, and identify optimization opportunities such as rightsizing, time-slicing, or autoscaling.
Why it matters: AI at scale without cost observability is unsustainable.
A cluster with 100 GPUs at 30% utilization still incurs 100% of the bill.
Engineers waiting on blocked jobs or resubmissions add hidden labor costs.
Executives eventually see AI as a “science project” rather than a business driver if costs balloon without clear ROI.
Cost monitoring turns AI from a runaway expense into a disciplined investment. It ensures teams don’t just ask, “Can we scale this?” but also, “Can we afford to keep scaling?”
Pillar 3: Model Health — Accuracy, Drift, and Business Trust
Press enter or click to view image in full size

Key Question: Is the model still making good predictions?
Infrastructure may be stable and costs under control, but if the model itself is drifting, the business is making decisions on faulty insights. Unlike software bugs, these failures are often silent: the system runs smoothly, dashboards show green, but predictions gradually degrade. By the time anyone notices, the business has already absorbed losses.
Focus: Accuracy and health monitoring ensures that models remain fit for purpose after deployment.
Data drift: The statistical properties of input data change (e.g., new customer behaviors, seasonal shifts, new fraud patterns).
Concept drift: The relationship between inputs and outputs changes (e.g., a model trained on old fraud tactics fails against new ones).
Metrics to watch: Precision, recall, click-through rate (CTR), fraud catch rate — chosen based on the business problem.
Tools: Platforms like Evidently AI, Arize, Fiddler.ai, and WhyLabs are designed for monitoring model health. They detect drift, track performance, and trigger retraining workflows before degradation reaches production impact.
Why it matters: Silent degradation is one of the most dangerous failure modes.
A recommendation engine that drifts can quietly reduce CTR and revenue over months.
A healthcare diagnostic model exposed to new populations can miss critical cases if concept drift goes undetected.
A fraud model that fails to adapt to new attack patterns can cost millions before alerts are raised.
Monitoring model accuracy ensures you’re not just serving fast (Pillar 1) and efficiently (Pillar 2), but also serving something worth trusting.
Case in Point: Monitoring That Mattered
A mid-sized e-commerce company struggled with hidden costs and user experience:
P99 latency spiked to >1s during peak traffic.
GPUs ran at 35% utilization, burning ~$80K/month.
Fraud detection accuracy slipped due to data drift.
By adding performance, cost, and model health monitoring (Grafana, Kubecost, Evidently), they cut latency by 75%, saved $500K annually, and restored customer trust.
👉 The lesson: AI observability isn’t optional — it drives both efficiency and revenue.
The Complete Observability Picture — Performance, Cost, and Accuracy Together
Each pillar of AI monitoring answers a different — but equally critical — business question:
Serving / Performance: Can we serve fast enough to meet user expectations and protect revenue?
Cost: Can we afford to keep serving at this scale without waste?
Accuracy / Health: Are we serving predictions that can actually be trusted?
On their own, each dimension tells part of the story. But together, they form the “glass box” view of AI observability — a transparent system where leaders, engineers, and executives alike can see how AI is performing, spending, and delivering value.
Miss even one of these, and the risks multiply:
Ignore performance, and inference stalls lead to frustrated users and lost business.
Ignore costs, and budgets spiral out of control, turning AI into a financial liability.
Ignore accuracy, and even the most efficient, fast-serving system quietly undermines trust with bad predictions.
When all three are measured and monitored together, AI shifts from being a black box that’s feared and mistrusted to a glass box that drives confidence, adoption, and ROI.
Closing the AI Execution Gap with ParallelIQ
At ParallelIQ, we help mid-market companies build AI observability stacks that catch hidden costs, performance stalls, and drift before they hurt the business. Don’t let your AI run blind — make it observable.
AI is already reshaping your industry. The winners won’t just be those with the biggest budgets — they’ll be the ones who can see clearly, act quickly, and trust their AI in production.
👉 Want to learn how observability can accelerate your AI execution?
[Schedule a call to discuss → here]



