


AI/ML and Model Operations
GPU Idle Time Explained: From Lost Cycles to Lost Momentum

The Silent Killer
What’s worse than paying for expensive GPUs? Paying for expensive GPUs that are doing nothing. A GPU sitting idle is like a 747 parked on the runway with engines running — burning fuel, going nowhere.
In AI workloads, idle GPUs are more common than most leaders realize. Jobs sit in queues, data pipelines crawl, containers restart, or developers simply step away while waiting for a blocked run to complete. On paper, the GPUs are provisioned and billed at 100%. In reality, only a fraction of that time is delivering useful work.
The impact goes far beyond infrastructure cost. Idle GPUs mean slower training cycles, frustrated engineers, and lost momentum across the organization. A single blocked job can derail a week’s worth of experiments, breaking focus and delaying insights. Over time, this compounds into wasted budgets, stalled projects, and missed market opportunities.
In this post, we’ll strip GPU idle time down to the basics — productivity, efficiency, overhead, and scalability — and show how it connects not just to machines, but to the humans behind them. Because idle time doesn’t just waste money — it kills execution.
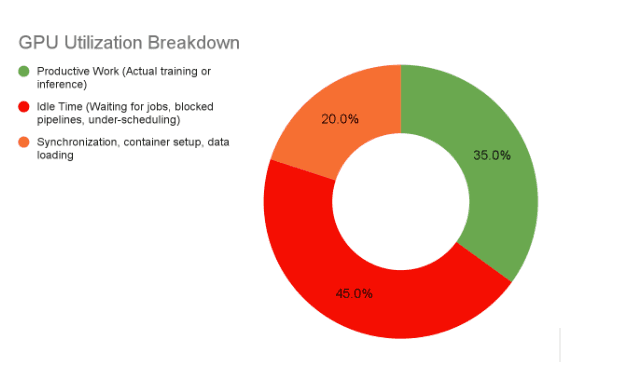
Back to Basics: Productivity, Efficiency, Overhead, and Scalability
Before diving into GPU idle time, it helps to revisit a few fundamentals from parallel computing:
Productivity → How much useful work gets done over a period of time. For AI, think of it as how many model iterations you complete in a week.
Efficiency → The ratio of useful work to total resources consumed. A GPU cluster running at 35% utilization is only one-third efficient — the rest is wasted cycles.
Overhead → The hidden tax on performance. Every stalled data pipeline, container restart, or synchronization delay eats into available cycles without delivering results.
Scalability → The ability to maintain efficiency as you add more GPUs. In practice, if you double the number of GPUs but your throughput only rises by 50%, idle time is compounding.
Efficiency
A simple way to think about it:
Efficiency = Useful GPU Work / Total GPU Time Paid For
If useful work = 30 hours but the cluster was running for 100 hours, efficiency = 30%. The other 70% is either idle or lost to overhead — yet the bill arrives at 100%.
Overhead and Scalability
Overhead doesn’t just eat into efficiency — it directly limits scalability.
In theory, if you double the number of GPUs, you should double throughput. But in practice, overhead also grows: synchronization across more nodes, more data shuffling, longer queue times, and higher communication costs.
That means:
Small scale → overhead might be 10%, efficiency still looks “ok.”
Large scale → overhead rises with system size, and suddenly half your GPUs are waiting instead of working.
This is why so many AI projects hit a wall when scaling from tens to hundreds of GPUs. Instead of faster results, they get ballooning idle time and escalating bills.
A simple way to put it:
Scalability = Speedup / Number of GPUs
If speedup doesn’t rise proportionally with GPUs, your scalability collapses. Idle time is the hidden tax that grows with scale.
Productivity
At its core, productivity in AI comes down to how many useful experiments or model iterations you can complete over a period of time. For a data science team, that might mean:
How many training runs can we fit into a week?
How quickly can we test new hypotheses?
How often can we push improved models into production?
Idle GPUs drag productivity down in two ways:
Slower Iteration Cycles → When GPUs are underutilized, every experiment takes longer. What should finish in hours drags into days, delaying insights and extending project timelines.
Human Switching Costs → Developers and researchers don’t just “wait around.” When training stalls, they switch to other tasks. Each context switch carries a cost — breaking flow, losing focus, and slowing the next round of iteration.
This means that productivity loss isn’t just about machines. It’s about people. A stalled run can waste hours of GPU time and just as many hours of engineer focus. Multiply that across a team, and the hidden productivity tax can be larger than the cloud bill itself. A simple way to think about productivity:
Productivity = Useful Experiments Completed / Total Time
If your team completes 10 meaningful training runs in a week, productivity 10/week.
If idle GPUs, long queues, or broken pipeline cut that in half, productivity falls to 5/week — Even though the cost of GPUs and engineers hasn’t changed.
In short: idle GPUs = idle humans = stalled learning. And in AI, stalled learning means slower business outcomes.
Sources of GPU Idle Time
GPU idle time isn’t caused by one thing — it’s the result of many small stalls across infrastructure, data, and people. Some of the most common sources include:
Scheduling Delays
Jobs is stuck in “pending” status because the scheduler can’t allocate GPUs efficiently. This is especially common when teams share clusters without fair scheduling or time-slicing.
Developer Wait Times
A model run that fails, hangs, or slows forces engineers to stop and wait. Even a short “coffee break” turns into hours of lost focus as context is lost.
Data Pipeline Inefficiencies
GPUs often sit idle while waiting for data to load, preprocess, or move across storage systems. Poorly optimized I/O pipelines can starve GPUs even when hardware is plentiful.
Platform and Orchestration Mismatches
Misconfigured containers, slow Kubernetes/Slurm job launches, or inefficient resource requests can delay training starts and waste cycles.
Synchronization Overhead
In distributed training, GPUs spend time waiting for others to finish their share of work before proceeding. As scale increases, so does this overhead.
Human Factors
Debugging complex ML systems is slow and iterative. When engineers spend cycles writing ad-hoc scripts to “kick” stalled jobs back to life, GPUs often wait idle in the background.
💡 Mini-example:
One startup team shared a 64-GPU cluster. On Friday afternoon, a new training job was submitted but sat in “pending” all weekend because no GPUs were available. The problem wasn’t the new job — it was that a previous job had failed to release its resources. The scheduler still marked those GPUs as “in use,” even though they were sitting physically idle.
From the provider’s perspective, the GPUs were still provisioned, so the cloud bill kept ticking. By Monday morning, not a single epoch had run, but three full days of capacity had been wasted — costing tens of thousands of dollars.
Press enter or click to view image in full size
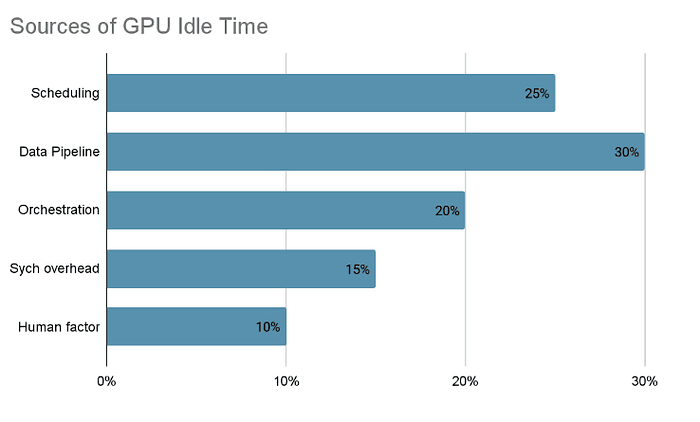
Idle time comes from everywhere — small inefficiencies compound into big losses.
The Human Cost: Switching and Momentum
While GPU idle time shows up clearly on a cloud bill, the hidden cost on teams is harder to quantify — and often larger.
Context Switching: When training jobs stall, engineers are forced to abandon focused work and jump to other tasks. Every switch breaks their mental flow, and regaining it later takes time. What could have been a 30-minute debug session stretches into half a day lost.
Lost Momentum: Machine learning thrives on fast iteration: run an experiment, learn, tweak, repeat. Stalls break that rhythm. Teams go from iterating daily to waiting days, and over time, they lose the cadence that drives breakthroughs.
Morale Impact: Few things frustrate data scientists more than “babysitting” jobs. Constant restarts and waits breed disengagement. Instead of experimenting boldly, teams pull back — reducing innovation and risking attrition.
Organizational Drag: Momentum isn’t just about individuals. Once iteration slows, roadmaps slip, deadlines move, and confidence in the AI program erodes. Executives start questioning ROI, and budgets shift elsewhere.
Retention Risk: Skilled ML engineers are scarce and expensive to replace. When they spend more time fighting infrastructure than building models, frustration builds. Burnout or departures create even greater hidden costs — lost knowledge, recruiting expenses, and months of onboarding before new hires reach full productivity.
💡 Mini-example:
A startup retail firm had a recommendation model that often failed overnight due to pipeline stalls. Engineers would arrive each morning to find no progress and spend hours restarting jobs. Within months, iteration cycles had doubled in length, and leadership began questioning whether the AI initiative was worth the investment at all.
Why This Matters to Startups Companies
Startups live and die by speed. Every wasted GPU cycle, every stalled pipeline, every delayed run eats into the most fragile assets a startup has: runway, iteration velocity, and team focus. Unlike hyperscalers or Fortune 500s, there’s no safety net — inefficiency isn’t just expensive, it’s existential.
Lean Teams, Higher Stakes
Startup ML and data teams are often tiny — sometimes just a handful of engineers. When those few people spend hours waiting on jobs or babysitting infrastructure, progress grinds to a halt. Every stall eats into scarce engineering cycles and slows product momentum.
Tighter Runway
Unlike hyperscalers or tech giants, startups can’t afford waste. A cluster running at 30% utilization isn’t a rounding error — it’s hundreds of thousands of dollars burned each year. That’s not just a financial drag — it shortens runway and risks survival.
The Execution Trap
Startups live and die by iteration speed. When GPU stalls and pipeline failures erode productivity, the team risks falling into the Execution Trap: knowing AI is critical but unable to operationalize it fast enough to keep pace with customer and investor expectations.
Talent Retention Risk
Top ML engineers join startups for impact, not to babysit infrastructure. If they spend more time fixing jobs than building models, frustration sets in. For a startup, losing even one key engineer can stall projects for months and jeopardize fundraising milestones.
💡 Executive takeaway
For startups, idle GPUs don’t just waste compute — they waste the scarcest resources of all: runway, talent, and momentum. Every stall isn’t just costly — it’s a direct threat to whether the company survives to its next round.
👉 At ParallelIQ, this is exactly where we step in — helping startups eliminate GPU waste, fix observability blind spots, and keep engineering teams focused on innovation rather than firefighting.
🚀 GPU stalls aren’t just a technical nuisance — they’re a startup killer.
Every hour of idle compute means fewer experiments, wasted runway, and frustrated engineers. For startups, where teams are lean and milestones are everything, the cost compounds quickly: iteration slows, investor confidence wavers, and survival is at risk.
The good news? These issues are solvable. With the right observability, scheduling, and data pipeline foundations, startups can scale their AI workloads with the efficiency of a tech giant — without carrying tech-giant overhead.
At ParallelIQ, we help startups:
🔍 Audit workloads to uncover hidden GPU waste.
📊 Build observability that flags stalls before they derail milestones.
💡 Free engineers to focus on innovation, not firefighting infrastructure.
👉 Don’t let idle GPUs become the silent tax on your runway. Measure idle time. Fix bottlenecks. Invest in observability. That’s how you turn GPUs from a burn into a growth engine.
📌 In our next article, we’ll share concrete strategies to cut GPU idle time — from smarter scheduling to resilient data pipelines.
#AIInfrastructure #GPUOptimization #StartupGrowth #CloudComputing #ParallelIQ



