


AI/ML and Model Operations
Data Is the New Moat: Why Mid-Market Companies Have What Startups Need

Introduction
“In the race to build AI, who actually owns the raw material — the data?”
AI-native startups are racing ahead with sleek infrastructure, cloud-first design, and in-house AI talent. They can move fast, launch products quickly, and win headlines.
But here’s the paradox: the richest, most domain-specific data — the kind of data that actually powers differentiated AI — doesn’t sit with those startups. It lives with mid-market incumbents who have been operating in their industries for years.
From transaction logs in financial firms, to patient records in healthcare, to listings and contracts in real estate, incumbents already own the goldmine. The problem? Their data is often fragmented, siloed, and locked inside legacy systems, making it hard to use for training or fine-tuning modern AI models.
This sets up the central tension: startups move fast, but incumbents have the fuel. The real question is whether mid-market companies can modernize their infrastructure and pipelines quickly enough to turn their data advantage into AI advantage.
The Startup Playbook for Data
Startups don’t usually begin with rich proprietary datasets. Instead, they stitch together strategies to get just enough data to train, test, and launch their AI products:
Public and Open Datasets → Kaggle competitions, open government data, and academic datasets often serve as the foundation for early models. It’s cheap and fast, but not always relevant to a specific vertical.
Synthetic Data Generation → Startups increasingly use generative methods or simulation to create artificial training sets when real-world data is scarce. It’s useful for bootstrapping, but may miss the nuances of live customer data.
Pilots with Early Customers → Offering free or discounted services in exchange for usage data. These pilots help refine models while simultaneously proving market demand.
Partnerships and Licensing Deals → Strategic collaborations with larger firms or data vendors to gain access to domain-specific datasets they couldn’t collect on their own.
Feedback Loops from SaaS Adoption → Every click, transaction, or interaction in the product feeds back into the model, gradually compounding data volume and quality.
The limitation? Startups start with scraps and scale into relevance. Their models can be nimble, but their early data is often thin and lacks depth. The real differentiator comes later, when usage snowballs and customer data feeds the loop. Until then, their edge lies in speed, not depth.
The Mid-Market Incumbent Advantage
Mid-market incumbents may lack the AI-native speed of startups, but they hold an asset that’s hard to beat: years of proprietary, real-world data.
Photos, transaction histories, sensor logs, customer interactions, operational records — this is the data startups dream of, because it’s grounded in real business activity and reflects industry-specific nuances.
Unlike generic public datasets, this data carries richness and domain specificity that’s almost impossible to replicate from the outside. It’s what makes fraud detection precise in finance, patient outcomes measurable in healthcare, and pricing models sharper in real estate.
But here’s the catch: most of this data is locked away in silos. It’s duplicated across systems, inconsistently formatted, and often lacks the labeling needed for AI training or fine-tuning. Without pipelines, governance, and observability, the advantage risks becoming a burden.
In other words, mid-market companies sit on a goldmine they can’t yet spend. Their challenge isn’t data scarcity — it’s data readiness.
The Strategic Tension
This creates a fascinating — and risky — push and pull between startups and incumbents:
Startups need data → Their biggest constraint is depth and domain relevance. To overcome this, they often partner with incumbents, or even poach customers outright, turning usage into training fuel.
Incumbents have data → They’re sitting on troves of proprietary records, but without modern infrastructure and pipelines, they struggle to turn that into working AI products.
The paradox → Some incumbents, instead of mobilizing their own data, end up adopting SaaS from startups. In doing so, they hand over valuable usage data that strengthens the competitor’s model — accelerating the very disruption they fear.
Press enter or click to view image in full size
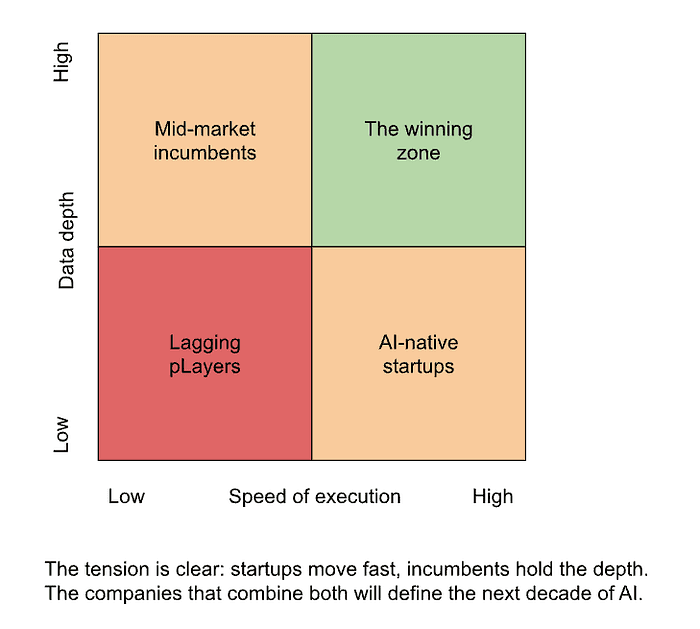
This is the heart of the execution gap: whoever can mobilize the data fastest wins. Startups win on speed; incumbents win on depth — if they can unlock it.
The Takeaway
In AI, data gravity matters more than model architecture. The shiniest algorithm means little without the right fuel.
AI-native startups win on speed and agility, building quickly and capturing attention. But mid-market firms already sit on the gold: years of proprietary, domain-specific data that no startup can replicate. The challenge isn’t data scarcity — it’s data readiness.
The winners of this race will be the companies that close the execution gap: pairing their unmatched data ownership with the right infrastructure, pipelines, and observability to put that data to work.
Those who succeed won’t just compete with startups — they’ll set the pace for their entire industry.
Closing Thought
AI success won’t be defined by who builds the flashiest model.
It will be defined by who can unlock the deepest data and put it to work.
Mid-market firms already have that advantage. The question is whether they’ll mobilize it — or watch AI-native startups catch up and seize the opportunity first.
Where ParallelIQ Fits In
At ParallelIQ, we help mid-market companies cut GPU waste, build observability into their pipelines, and modernize infrastructure — so they can move as fast as AI-native startups without losing control of their business.
Don’t let execution slow you down. The gap between potential and production is where most AI projects fail — and where ParallelIQ helps you win.
👉 Want to learn how to optimize resources, embed observability, and accelerate your AI execution? [Schedule a call to discuss → here]



