


AI/ML Model Operations
Beyond Prompt → Code: The Real Systems Challenges Behind Coding Foundation Models
Most people think coding AI works like prompt in, program out. At the surface level, that is true. However, serious coding platforms (Cursor, Magic.dev, Copilot, etc.) go deeper. In these platforms, the model is the easy part. The execution system is the hard part.
This article explores the real systems challenges behind modern coding foundation models — across training, inference, and agent workflows — and why the next bottleneck isn’t better models, but better control planes.
Coding Models Are Not Just Text Models
Unlike LLMs that operate on flat token sequences, code is:
Structured (ASTs)
Typed
Dependency-graph based
Semantically constrained
Multi-file and hierarchical
For instance, when you ask to refactor authentication in a repo, the model must approximate cross file dependencies, import resolution, interface compatibility, behavioral invariants and test expectations. That is no longer autocompleted. It is a probabilistic program transformation using a structure. The transformer just sees tokens.
Training Is Only the First Half of the Story
Pretraining
In foundation coding models the objective is next-token prediction. These models are trained on public repositories, commit diffs, PR conversations, stack traces, documentation and tests. But coding data presents unique issues such as:
Duplicate repos
Boilerplate
License contamination
Secrets
Low-quality code
Outdated APIs
Filtering and deduplication pipelines become critical. Moreover, long context training introduces new scaling challenges such as memory explosion, communication overhead, instability at large sequence lengths and reduced effective batch size.
Post-Training: Where Coding Gets Hard
Unlike chat models, correctness in coding is binary means whether the code compiles, tests pass, and does anything break in a different module. Modern coding systems often use feedback mechanisms such as use of multiple candidate patches, running tests, keep passing solutions and fine-tune on successful outcomes. Now training is no longer just gradient updates. It becomes a generation cluster, test execution cluster, aggregation pipeline and filter infrastructure which becomes part of the learning signal.
Inference Is Where the Real Complexity Emerges
A production coding assistant rarely performs a single model call. It performs a workflow. Before inference even begins, the system must:
Index the repo (AST + embeddings + symbol graph)
Retrieve relevant files
Inject style guides
Inject test files
Inject error messages
Assemble structured context
The model sees tokens. But the product is doing graph traversal, retrieval, and compression.
The Hidden Monster: KV Cache
Large context means large memory footprint. KV memory scales roughly with:
batch_size × sequence_length × num_layers × head_dim
Now combine 100k+ token contexts, multi-user sessions, agent retries and persistent sessions and you get GPU memory fragmentation, OOM spikes, admission failures and throughput degradation. This is not just a model problem. This is a memory scheduling problem.
Latency vs Throughput Tradeoffs
Not all coding tasks are equal. Autocomplete has these requirements:
Low latency requirement
Small context
Small model
While repo refactor requires:
Large context
High memory footprint
Less latency sensitive
Larger model
If you treat all requests equally, you waste resources. You need model-aware routing and admission control.
The Agent Loop Changes Everything
Modern coding platforms increasingly operate in agent mode as shown in the following diagram:
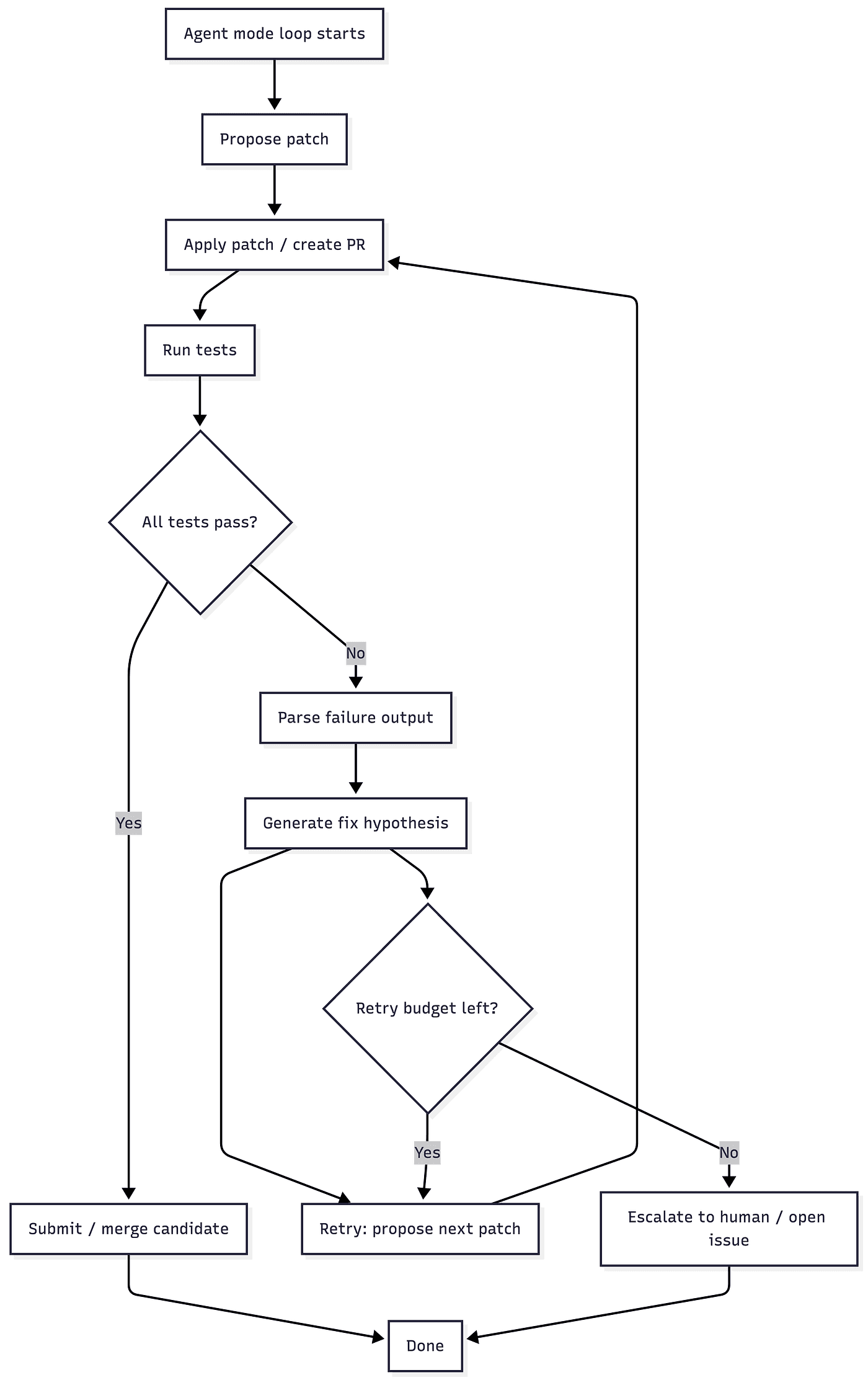
Closed-Loop Agentic Code Execution Workflow
Furthermore, multiple patches are scored to select the best candidate. Note that this is simplified as fail/pass criteria depends not only on the tests but also on static analysis, confidence score and regression results.
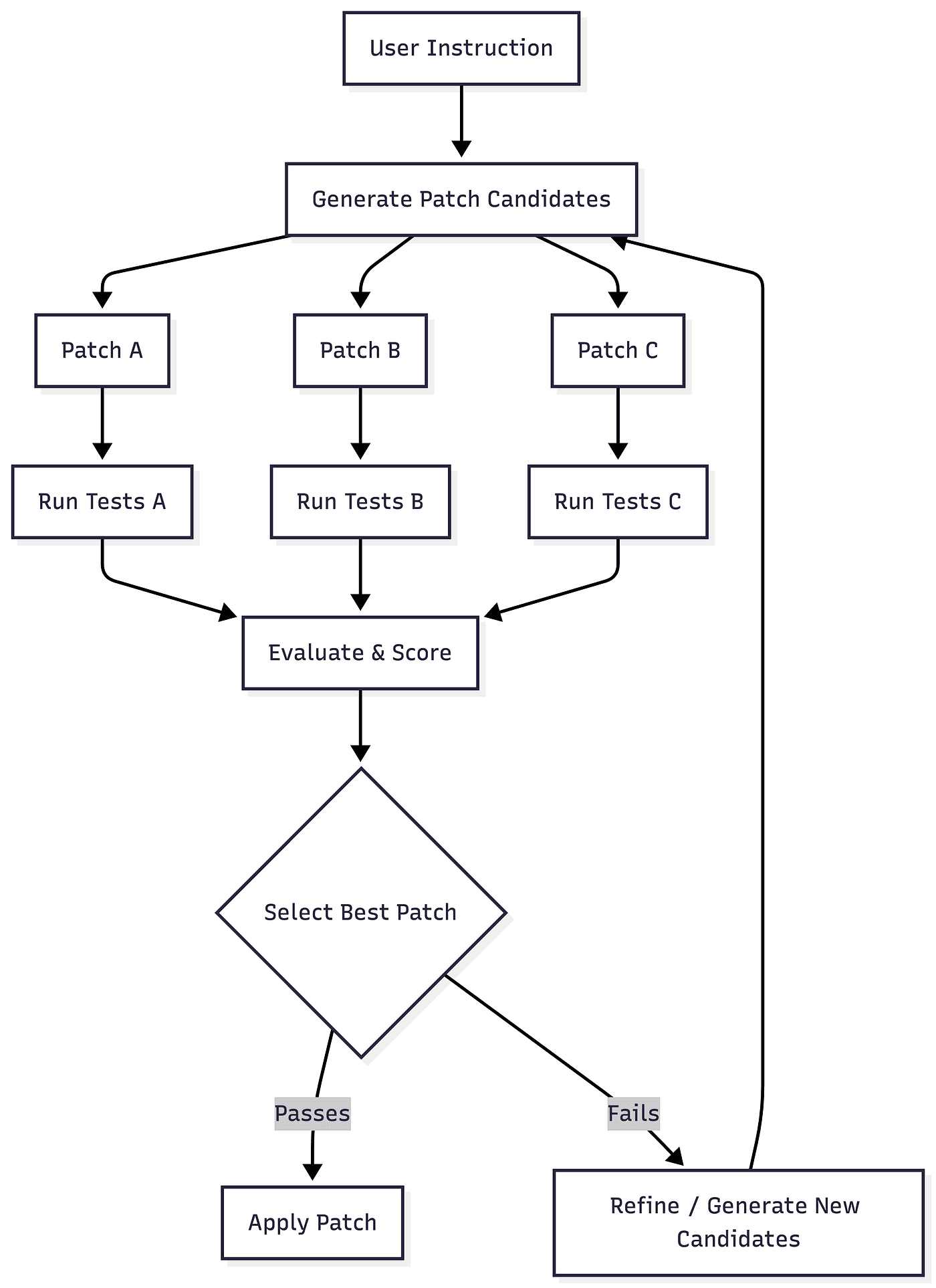
Multi-Candidate Patch Generation and Selection Pipeline
With all this, inference becomes stateful, iterative, non-deterministic and multi-resource. Sessions grow in memory. Tool calls add CPU and IO load. Retries increase cost unpredictably. This is orchestration complexity — not text generation.
Repo-Level Reasoning Is the Real Leap
Early coding benchmarks focused on single-function generation. Real-world workflows require repo-level reasoning where multiple files may need to be updated coherently, preserve cross-module invariants, updating tests and respecting project conventions and all this while avoiding regressions. This type of a agentic system requires:
Long context
Retrieval systems
Cross-file awareness
Execution validation
The gap between file-level and repo-level reasoning is massive. And it pushes infrastructure to its limits.
What Breaks at Scale
As coding platforms grow, the bottlenecks shift:
1. Context Windows Explode
200k+ token contexts stress memory and scheduling.
2. Agent Sessions Persist
Long-lived sessions fragment GPU memory.
3. Tool Loops Dominate Latency
Tests and builds become execution bottlenecks.
4. Cost Predictability Becomes a Product Requirement
Enterprise customers want:
Budget caps
Cost per PR
Model selection policies
Governance controls
5. Multi-Model Routing Becomes Mandatory
Small model for autocomplete. Large model for deep reasoning. Specialized model for refactors. And this multiplies complexity.
The Real Next Bottleneck: The Control Plane
As models improve, the differentiator moves upward. The new bottleneck is:
Admission control
Placement
Lifecycle management
Telemetry
Cost governance
Model-aware scheduling
Most infrastructure layers are hardware-aware, cluster-aware and Kubernetes-aware. However, very few are model-aware, context-aware, KV-cache-aware or agent-session-aware. Coding platforms need execution systems that understand:
How much memory a task will consume
How long it might run
Which GPU class is appropriate
When to route to smaller models
When to reclaim resources safely
How to reconcile intent vs reality
This is not just serving. This is control-plane design for AI execution.
The Convergence of Compilers, HPC, and AI
There’s a structural symmetry emerging:
Coding models approximate program transformations.
Agent loops resemble incremental compilation.
Long-context reasoning mirrors dependency graph traversal.
Inference scaling echoes parallel execution scheduling.
Distributed serving starts to look like a data-center networking problem.
The future of coding AI is not purely an ML problem. It is a systems problem that sits at the intersection of:
Compiler semantics
Distributed systems
GPU memory management
Workflow orchestration
Cost governance
The next breakthroughs won’t come from bigger models alone. They will come from principled systems that can reason about execution, state, and resource constraints as first-class concerns.
Closing Thought
The first wave of coding AI was about generating code. The next wave is about:
Safely modifying entire systems
Operating reliably at scale
Being predictable under load
Managing cost and memory intelligently
Closing the loop between intent and execution
The model is necessary. But the control plane is inevitable.



