


Cloud Providers and Infrastructure
Bare Metal vs. Hyperscaler: Why Startups Chase Raw GPU Capacity

Intro: The GPU Hunger Games
AI today runs on one scarce resource: GPUs. Training a large model or running inference at scale can consume thousands of GPU hours in a matter of days. The demand is so intense that access to GPUs has become a competitive advantage in itself — startups with capacity move faster, while those waiting in queue fall behind.
For most of the industry, the default answer has been the hyperscalers: AWS, GCP, Azure. They offer virtually unlimited cloud resources, enterprise-grade tooling, and a massive global footprint. But increasingly, startups are looking elsewhere. Instead of wrapping themselves in the hyperscaler ecosystem, they’re chasing bare metal GPU providers and VPS-based GPU clouds — companies that offer raw, unabstracted access to high-performance hardware.
Why? Because at the early and growth stages, the battle isn’t about fancy managed services or polished dashboards. It’s not about bells and whistles — it’s about raw capacity, cost, and speed. A startup needs GPUs they can afford, control they can trust, and performance that doesn’t hide behind layers of cloud abstractions.
Hyperscalers aren’t without merit. They’ve built their dominance by offering a vast menu of managed services: autoscaling clusters, integrated MLOps platforms, enterprise-grade compliance, and global reach. For large enterprises with complex needs, that convenience is worth the premium. But for a startup burning investor dollars and racing to market, every layer of abstraction comes with a cost. What looks like flexibility on paper often translates to higher bills, slower experimentation, and less control. This is where bare metal and VPS GPU providers carve out their niche — giving young companies the raw horsepower they crave without the hyperscaler overhead.
The Hyperscaler Value Prop: What They Offer
The big three cloud providers — AWS, GCP, and Azure — have built an empire around convenience and breadth. Their value proposition is clear:
Managed services everywhere: From Kubernetes clusters to managed ML pipelines and spot markets, hyperscalers abstract away much of the operational heavy lifting. Engineers can focus on models while the cloud automates scaling, failover, and maintenance.
Elastic scale on demand: Need to go from 10 GPUs to 1,000 overnight? Hyperscalers can make it happen with a few clicks. That flexibility is hard to beat.
Enterprise-grade security and compliance: For industries like healthcare, finance, and government, hyperscalers’ compliance certifications (HIPAA, SOC2, FedRAMP, etc.) are often non-negotiable.
An integrated ecosystem: Storage, networking, data lakes, analytics, AI APIs — all tightly coupled and ready to plug into the same cloud fabric. This means less integration work and fewer moving parts to manage.
For enterprises, this combination is gold. They can pay the premium for convenience, regulatory peace of mind, and global infrastructure. But for startups, the equation is very different. The hyperscaler toolkit often feels like using a space shuttle to commute across town: powerful, sophisticated, and loaded with features — but unnecessarily expensive and complex when what you really need is raw, affordable horsepower.
The Bare Metal / VPS Appeal: Why Startups Like It
For a startup, every GPU hour matters. Runway is finite, investor updates are looming, and the only real question is: how fast can we train and deploy? Bare metal and VPS GPU providers answer that with a simple promise — raw power at a fraction of the cost.
Cost efficiency: Prices are often 3–5× lower than hyperscalers for the same silicon (think H100s or A100s). That difference can turn a six-figure cloud bill into something survivable — a massive advantage when every dollar counts.
Press enter or click to view image in full size
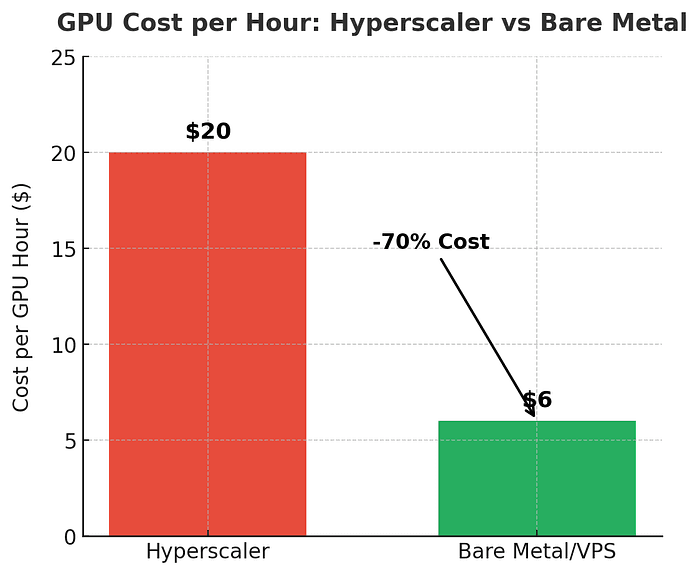
Control: You’re not locked into managed abstractions. With root access and full OS control, teams can install custom drivers, fine-tune configurations, and squeeze every ounce of performance from their hardware.
Performance: Without the virtualization layers and orchestration overhead common in hyperscaler environments, workloads run closer to the metal. That means better utilization of PCIe and NVLink bandwidth — critical for large model training.
Simplicity: Instead of navigating 20 different services and dashboards, you get what startups often want most: a clean, powerful box with GPUs. Spin it up, drop in your stack, and start training.
For fast-moving teams, this isn’t just convenience — it’s survival. Startups want speed to experiment, not bureaucracy. Bare metal clouds give them the shortest path from idea to model, without draining their budget in the process.
The Trade-Offs
Neither path is perfect. Both hyperscalers and bare metal GPU providers come with their own set of compromises — and the right choice depends on what stage you’re at and what risks you can afford to take.
Bare Metal / VPS Clouds
Limited elasticity: Capacity is not infinite. When demand spikes — or when the latest GPUs are in short supply — you may find yourself waiting in line.
Fewer managed tools: You get the hardware, but you’re responsible for everything else — job scheduling, monitoring, observability, and scaling. That means more engineering effort in-house.
Variable compliance and reliability: Many bare metal providers don’t match hyperscalers’ enterprise certifications or global SLAs. For some industries, that can be a deal-breaker.
Hyperscalers
High cost: Their GPUs are often 3–5× more expensive than bare metal equivalents, and those costs multiply quickly as workloads grow.
Lock-in risk: Once you build deeply into AWS, GCP, or Azure’s ecosystem, it’s hard to leave. Pricing and architecture decisions can end up shaping your strategy more than you’d like.
Complexity overhead: With so many services to configure and maintain, engineers often spend more time on infrastructure than on model development.
Press enter or click to view image in full size
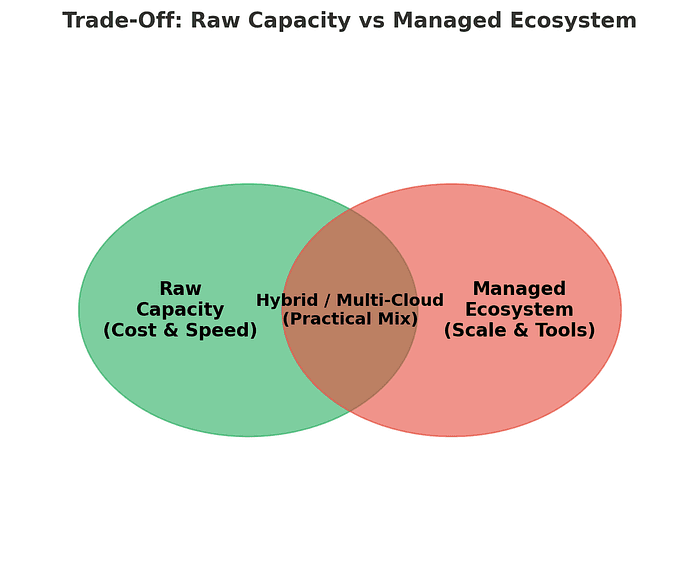
In short: bare metal gives you raw speed and savings, hyperscalers give you resilience and reach. The challenge for startups is deciding which set of trade-offs matters less at their stage of growth.
The Startup Journey: A Real-World Pattern
When it comes to infrastructure, most startups follow a predictable path. It’s less about ideology and more about survival and maturity — the needs change as the company grows.
Early Stage → Bare Metal / VPS
At seed or Series A, speed and cost dominate. Founders want GPUs they can actually afford and environments they can control. Bare metal or VPS providers deliver just that: no-frills horsepower to iterate quickly and prove product-market fit without burning through investor dollars.Growth Stage → A Mix of Both
By Series B or C, the company is running multiple workloads — training, fine-tuning, inference — often across different teams. At this point, startups begin blending bare metal with hyperscalers: bare metal for heavy lifting (training) and hyperscalers for elasticity (serving spikes, customer-facing workloads, or global distribution).Later Stage → Hybrid or Multi-Cloud Strategy
Once the company is scaling into new markets or approaching enterprise customers, the priorities shift again. Compliance, SLAs, and global availability can no longer be afterthoughts. Many move to a hybrid or multi-cloud strategy — balancing bare metal cost efficiency with hyperscaler reach, governance, and resilience.
Press enter or click to view image in full size
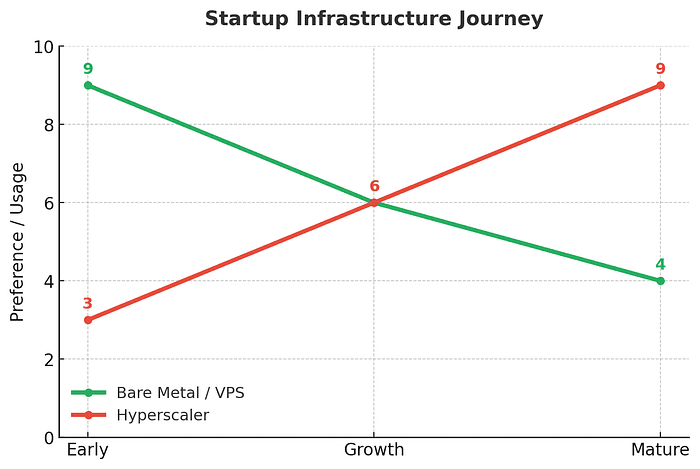
This journey looks like a maturity curve: early on, raw capacity is king; later, resilience and compliance share the spotlight. The smartest teams don’t lock themselves into one camp but adapt their infrastructure mix as they climb the curve.
Where Infrastructure Matters (The ParallelIQ Angle)
Choosing between hyperscalers and bare metal is only part of the story. The real challenge isn’t where you run your workloads — it’s how efficiently and reliably they run once you’re there.
Startups chasing raw GPU capacity often discover hidden costs:
Observability gaps: Idle GPUs, drifting models, or silent bottlenecks that quietly eat budgets.
Workload inefficiency: Without smart scheduling, monitoring, and resource tuning, even the best GPUs underperform.
Scaling risks: A sudden spike in users or training demand can overwhelm fragile infrastructure, leading to outages or costly fire drills.
This is where ParallelIQ steps in. We act as the neutral infrastructure partner, helping companies extract maximum value from their GPU spend — whether they’re running on hyperscalers, VPS providers, or a mix of both.
Our focus is building the foundation: observability baked into pipelines, efficient job execution, and infrastructure that scales without collapsing under pressure. By closing these gaps, we help startups double their release speed, cut GPU costs by up to 40%, and scale confidently as they grow.
Closing: Choosing Smart, Not Just Choosing Sides
Bare metal gives startups what they crave most — speed and savings. Hyperscalers, on the other hand, deliver scale and services that become critical as companies mature. The truth is, the best infrastructure strategy usually isn’t about picking one side. It’s about finding the right mix for your stage, your workloads, and your budget.
That’s where ParallelIQ comes in. We help teams avoid waste, maximize GPU ROI, and stay flexible — whether they’re running on bare metal, VPS clouds, or hyperscalers. Our focus is building the foundation that keeps your AI stack efficient, observable, and scalable no matter where it runs.
👉 Want to cut GPU waste and speed up releases? Let’s talk -> Here.



